
Welcome ☀️
Hi, I’m a data scientist with a background in engineering and a strong interest in turning complex data into meaningful stories and smart decisions. Over the past few years, I’ve worked on marketing analytics, recommendation systems, predictive modeling, and automation projects for brands like Uniqlo Indonesia, ASICS Indonesia, ERHA, This Is April, and Primer Group of Companies.
If you want to know more about me, click here!
Current WIPs:
- Customers’ RFM Segmentation: Building an RFM (Recency-Frequency-Monetary) pipeline to segment customers into actionable groups that enables targeted retention and reactivation campaigns.
mlbundlepackage: A lightweight bundler module that saves/loads preprocessing, the trained model, label decoding, and optional postprocessing so inference works the same outside notebooks.
Blog
Brain dumps and everything in between ✨
First Post
2025-12-23
I needed a new blog as a place to think out loud and explore ideas in a bit more depth, especially around data science, machine learning, and the things I’m learning or curious about. Sometimes a project or topic deserves more space than what social media nowadays usually allow, and this blog gives me that room.
It’s also a way for me to get back into long-form writing. Writing helps me organize my thoughts, reflect, and stay sharp, and it’s something I’ve missed doing regularly. Beyond technical posts, you might find the occasional personal musing here too. Hopefully, this space grows into a useful archive of ideas and lessons learned along the way.
Read morePortfolio
Projects that I’ve done ✍️
3-Stage (AgglomerativeClustering + 2-Stage Hierarchical LinearSVC) News Topic Classifier
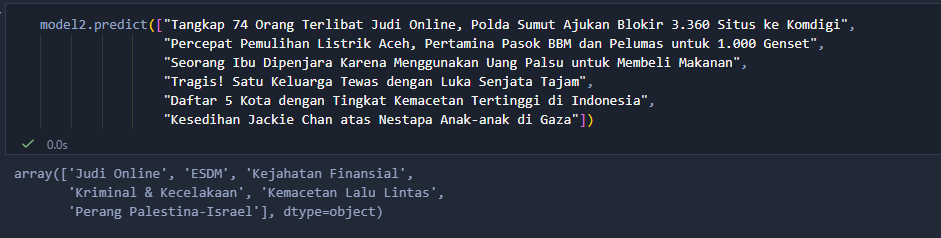
This projects trains a hierarchical text classifier for Indonesian articles using TF-IDF features + LinearSVC, with a data-driven “aggregate topic” stage built via AgglomerativeClustering. Validated on two case studies:
- an unlabeled Indonesian news corpus (Kaggle 2025) that I labeled efficiently via a cluster-first workflow (SentenceTransformers + BERTopic, then selective manual labeling)
- a finance-topic dataset consisting of short, headline-like sentences (avg. ~118 characters), to test robustness across different text lengths and class imbalance.
PyTorch Implementation of Nested Logit Mode Choice Model with Heterogenous Features + Dynamic Pricing Tools
Demo | Demo (Streamlit) | GitHub
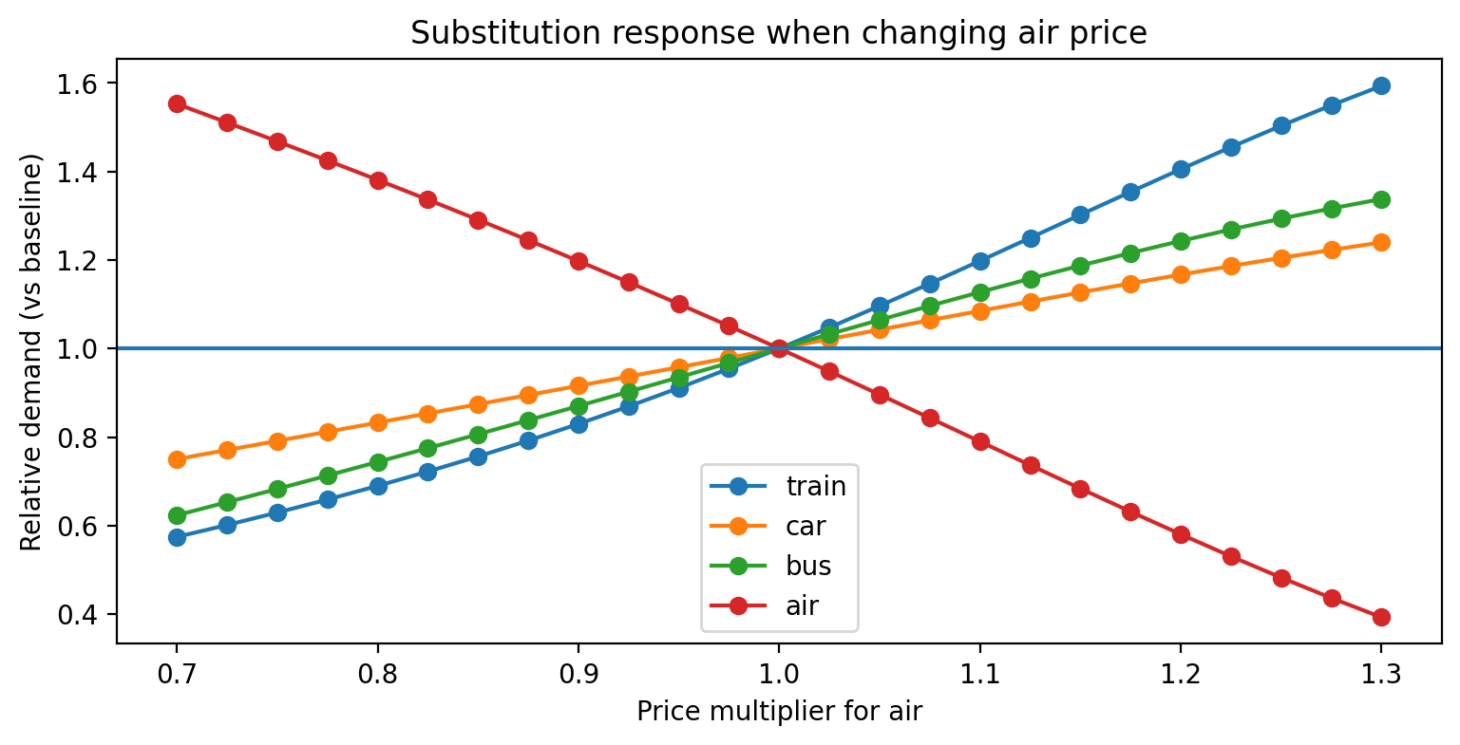
This is a nested logit discrete choice model implemented in PyTorch and deployed as a Streamlit app (containerized with Docker). The public ModeCanada dataset is used to model travel mode choice across train, car, bus, air using a two-level nest structure (Land vs. Air) where Land = {train, car, bus} and Air = {air}. Heterogeneous effects introduced via income and urban features. The project is framed as a hypothetical travel-agency e-ticketing case study, where train recall is prioritized to reduce missed public transport demand signals.
Read moreEcommerce Book Sales Forecast Using Prophet
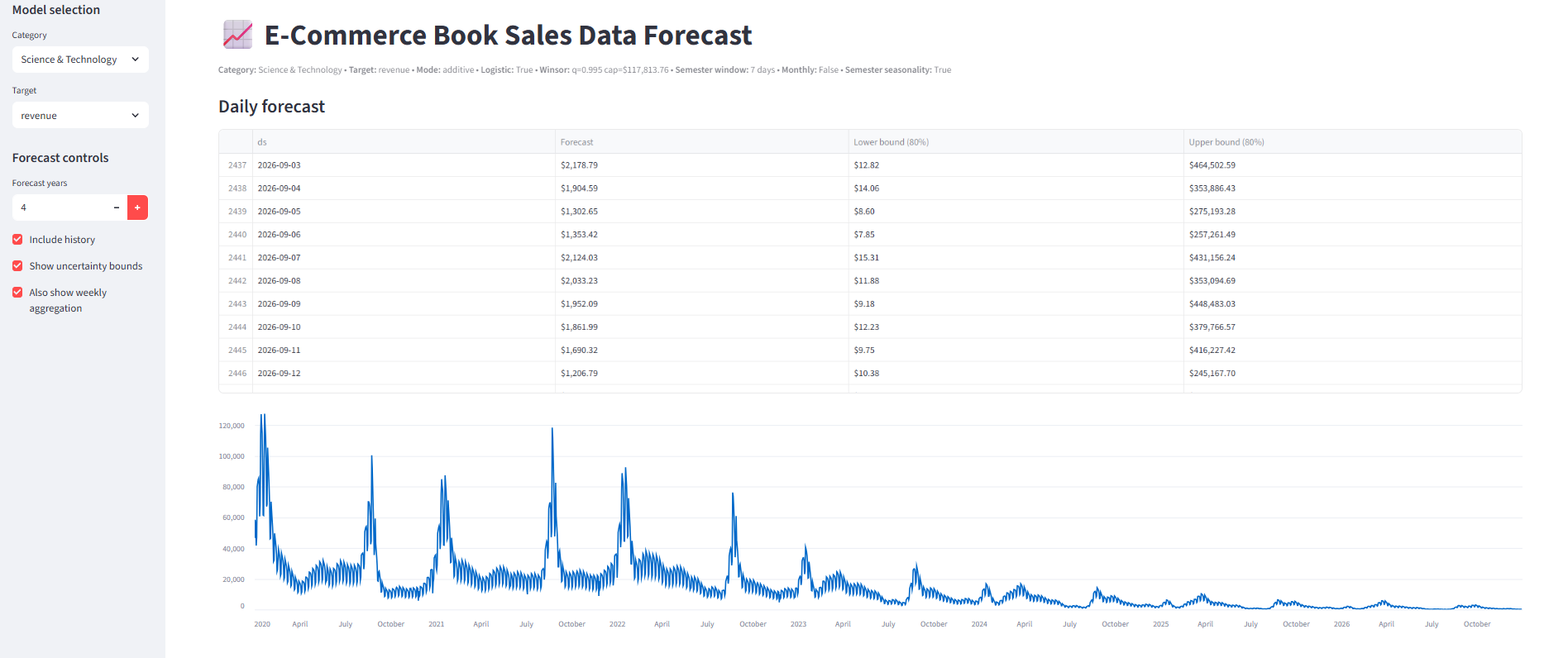
This is a time series forecasting pipeline built using Prophet to predict qty and revenue per category using daily ecommerce book sales data from 2020-2022. The model was tuned using a grid search with a time-based holdout split (train before 2022-01-01, test from 2022-01-01 onward) over key Prophet hyperparameters (seasonality mode, changepoint/seasonality priors, yearly seasonality), and enhanced with holiday effects and additional custom seasonalities (monthly/semester). Accuracy was measured using WAPE and MAE at both daily and weekly-aggregated levels, with a 7-day seasonal naive baseline (t-7) used for context.
Customer Retention Analytics Dashboard
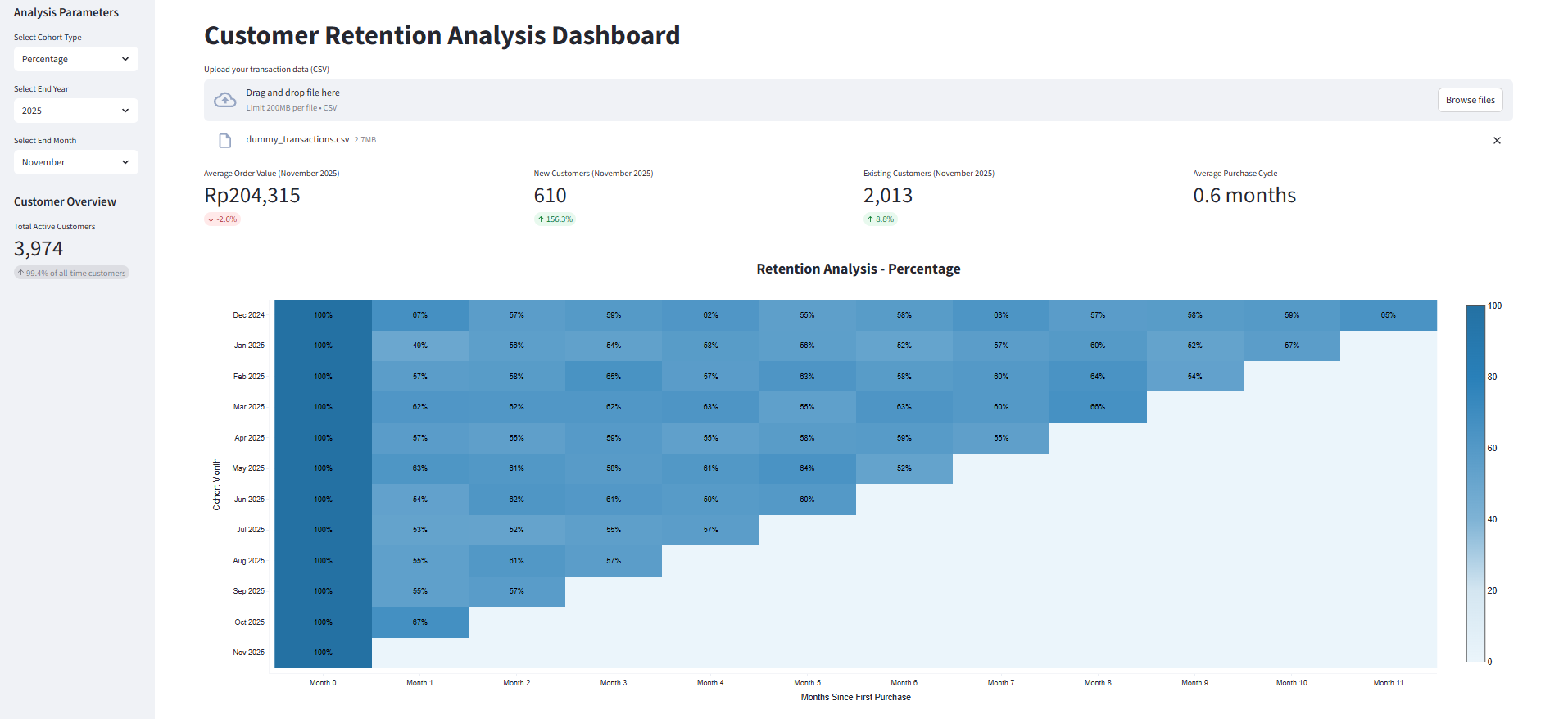
A Streamlit application for analyzing customer retention patterns using cohort analysis.
Read more